这篇文章主要调研的是一种常见的改进在线语音识别的方法:序列区分性训练(Sequence Discriminative Training)。相信有很多人已经在 CTC/CE 的训练上遇到了瓶颈,而一些新的框架如 RNN-T,End2End 的实现,对于工程上的改动比较大。这个时候考虑序列区分性训练是一个非常实惠的方式,基于 CE/CTC 稳定下来的模型,接入序列区分性训练,收益非常可观且工程代码不用修改,只需要后期 tune 一下参数就好。文末会给出我最近看到的一些有助于实现该功能的 Repo。
这篇文章可能文字讲解的地方会比较少,因为图片的内容信息量已经很大了,同时论文的出处我会一并放出,有兴趣的朋友可以阅读下原文。
实时系统的训练准则对⽐
Frame-Level Criterion
Cross Entropy:
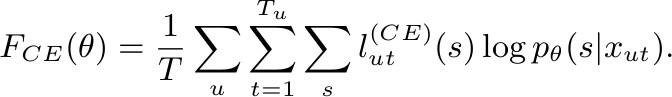
CE Loss 公式
End-to-End Criteria
- Connectionist Temporal Classification:
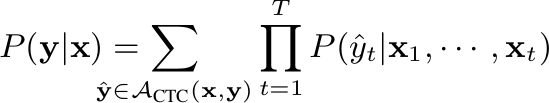
CTC Loss 公式
- RNN-T:
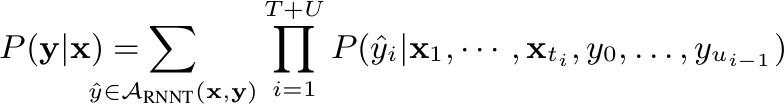
RNN-T Loss 公式
Sequence-Level Criteria
- Maximum Mutual Information:
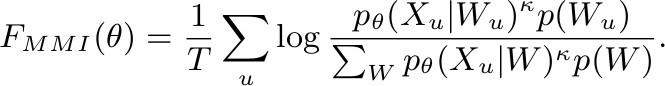
MMI Loss 公式
该 loss 出了对带浅层语言声学模型做基于词序列的标准解优化之外,还对竞争路径做了区分优化。
Ref:Sequence-discriminative training of deep neural networks
- Minimum Phone Error or state-level Minimum Bayes Risk:
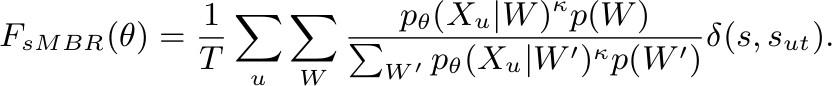
sMBR Loss 公式
基于MMI的进一步优化是,对标准路径做了相似路径优化扩充,引入了序列相似度打分,旨在缩小类内距离同时放大类外距离。
Ref:Sequence-discriminative training of deep neural networks
下面是谷歌在做区分训练的实时训练流程,
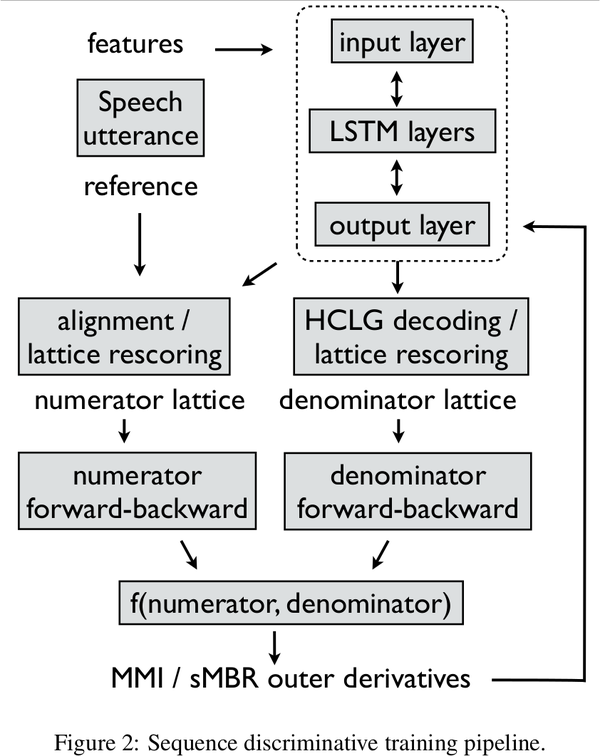
谷歌的 sMBR 训练流程
Ref: Sequence Discriminative Distributed Training of Long Short-Term Memory Recurrent Neural Networks
论⽂中的实验对⽐
本章实验内容主要分享中英文下各种设置对于 sMBR 准则训练的影响。序列区分性方法可以基于 CE 或 CTC 预训练稳定后接入,从下面的实验来看收益在 5~10%。
Model Units
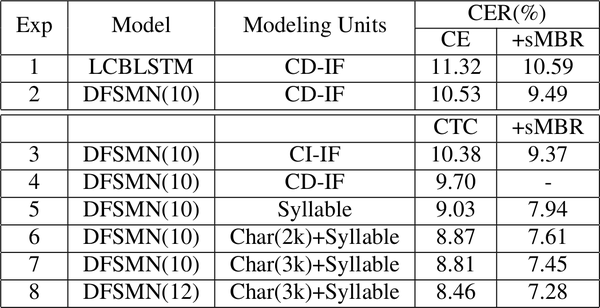
中文 Model Units 以及 CE/CTC sMBR 的实验对比
Ref: Investigation of Modeling Units for Mandarin Speech Recognition Using Dfsmn-ctc-smbr
Frame Rate
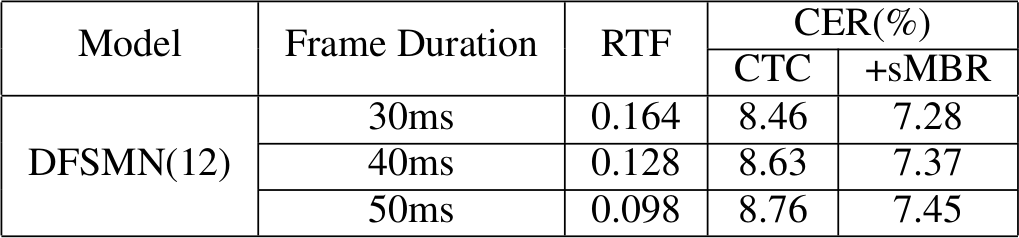
Frame Rate 对 CTC sMBR 的影响
Ref: Investigation of Modeling Units for Mandarin Speech Recognition Using Dfsmn-ctc-smbr
SDT language model

不同的 N-GRAM 模型对于 sMBR 训练的影响
Ref: Sequence Discriminative Distributed Training of Long Short-Term Memory Recurrent Neural Networks
Training Strategy
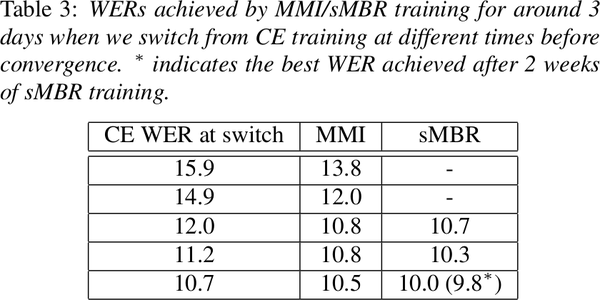
不同的 CE 预训练阶段切换对于 MMI/sMBR 的影响
Ref: Sequence Discriminative Distributed Training of Long Short-Term Memory Recurrent Neural Networks
Noisy Dataset
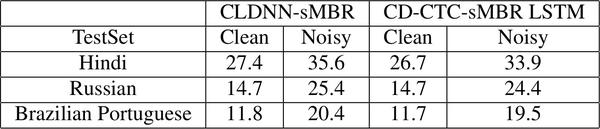
CE-sMBR 和 CTC-sMBR 在不同数据类型下的对比
Ref: FLAT START TRAINING OF CD-CTC-SMBR LSTM RNN ACOUSTIC MODELS
开源项⽬
CTC-CRF
清华⼤学开源的项⽬,欧老师 和学生 Keyu An, Hongyu Xiang 共同研发并开源的一套 CTC-CRF 区分训练方法,Hongyu Xiang 实现了 WFST 的解码在 GPU 中并行运算,解码速度非常快。目前在几个标准集上都有 state-of-the-art 结果。
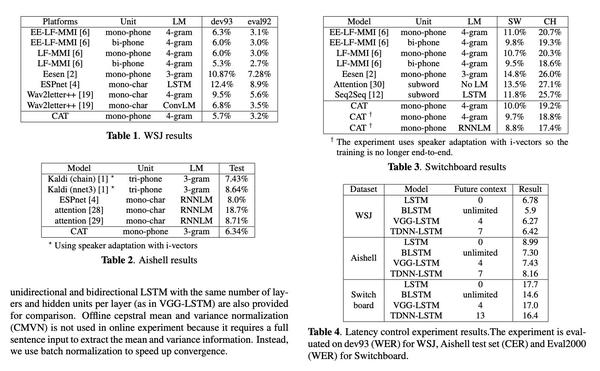
CTC-CRF 在各种标准集下的表现情况
Ref:CAT: CRF-based ASR Toolkit
团队完成了 PyTorch 的 binding。由于我主要是在 TensorFlow 上实现训练流程,所以基于此,稍微重构了些代码,完成了 Tensorflow 的 binding TeaPoly/warp-ctc-crf。另外 TensorFlow 的训练工具也在最近上传了,地址为 TeaPoly/cat_tensorflow。
使用公司内部的远场的 2MB 左右的小模型也取得了一定的收益,具体如下:
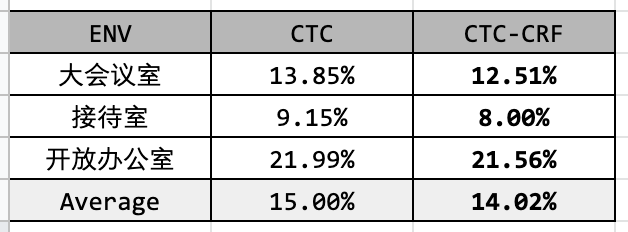
远场识别小模型引入 CTC-CRF 后的提升
EESEN
Yajie Miao 基于 Kaldi 工具完善的⼀套 CTC 训练框架。虽然没有使用目前主流的 TensorFlow/PyTorch 框架,但放到现在任然有⼀定的参考价值,⽬前尚未⽀持区分训练。
PyChain
小⽶语音组成员开发,Daniel Povey 参与,基于 LF-MMI chain model。基于 PyTorch 框架开发,提供了详细的 Pipeline 样例,同时完成了 FST 和 PyTorch 的 binding。
tf-code-acoustics
hubo 开发,从代码看应该是 Sogou 成员,作者相当勤奋,完成了MMI/MPE/sMBR/CTC/CE 的 TensorFlow 下的训练代码。和原作者沟通下来,他基于 CE/CTC-sMBR 做了尝试,相⽐于单纯 CE/CTC 都有 5% 到 10% 的收益。系统里有 Pipeline 和样例。 虽然目前没有特别完备的开发⽂档,但是作者的开源精神和勤奋程度让人佩服。