神经网络的推理中会涉及大量的向量或矩阵运算,在 PC 端我们通常会调用一些如 OpenBLAS、IntelMKL 等性能较好的向量加速库,在 ARM 芯片上也有自家的 CMSIS 加速库。而这些库的底层除了利用处理器的并行化能力,还会调用指令集优化代码。
这里我们介绍一种常用的优化方式 SIMD (Single Instruction, Multiple Data,单指令多数据流) 指令集。该指令集能一次性获得所有操作数进行运算,非常适合于多媒体应用等数据密集型运算。
单指令流多数据流(英語:Single Instruction Multiple Data,縮寫:SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。
在如今深度学习如此汹涌澎湃的时代,SIMD 优化的应用几乎无处不在,上至云端下至移动端。掌握这部分技巧对于神经网络的落地会有不少益处。
我会以两个向量相加为例,一步步引入 SIMD 的计算,同时我也会将相关的官方文档整理在其中。本文可以作为新手快速入门教程。
Pure C
下面是一个基础版本,当我们在优化函数时,一个正确的参考函数尤为重要(此函数输出可作为做 GTest 测试单元的参考输出),而最简单的实现方式就是一个好的开始。
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
int i = 0;
for (i = 0; i < n; i++) {
z[i] = x[i] + y[i];
}
}
我们知道指针的访问会比数组索引效率来的更高一些,所以我将上述代码的数组索引修改成指针的访问的形式。
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
int blocks = n;
while (blocks > 0U) {
*(z++) = (*(x++)) + (*(y++));
/* Decrement the loop counter */
blocks--;
}
}
后续在进行 SIMD 优化时,SSE2 指令和 NEON 指令会将一次性加载 4 个浮点计算,所以我们可以将一个 loop 每次运算一次向量加修改成一次运行4次向量加,这样可以快速的适应上 SIMD 的优化。同时由于减少了条件判断的打断,运算速度上也会比上一个版本速度要快些。 另外,需要注意的是我们接口中的参数 n 不能保证是整除 4 的,因此需要将剩余的部分做上一个版本一样的向量加操作。
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
int blocks;
/*loop Unrolling */
blocks = n >> 2U;
while (blocks > 0U) {
*(z++) = (*(x++)) + (*(y++));
*(z++) = (*(x++)) + (*(y++));
*(z++) = (*(x++)) + (*(y++));
*(z++) = (*(x++)) + (*(y++));
/* Decrement the loop counter */
blocks--;
}
/* If the blockSize is not a multiple of 4, compute any remaining output samples here.
** No loop unrolling is used. */
blocks = n % 0x4U;
while (blocks > 0U) {
*(z++) = (*(x++)) + (*(y++));
/* Decrement the loop counter */
blocks--;
}
}
Intel’s SSE Family Instructions
在进入使用 SSE 优化之前,我们必须清楚一个概念,过去我们意识中是一个数和一个数进行计算。如下图所示:
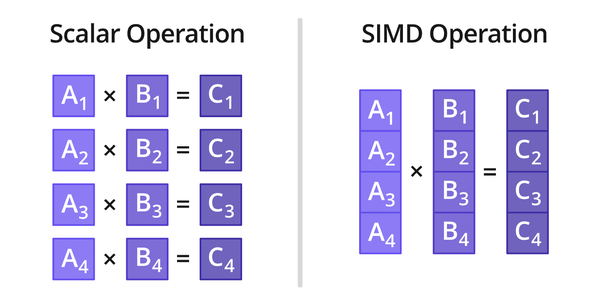
在 SIMD 的世界里,是用时将多个数和多个数之前进行并行运算。包括 GPU 在内的加速也是利用了线程的并行运算优势,而且 GPU 的线程数远远超过 CPU。
- SSE/AVX 的 API 的说明文档可以参考:Intel® Intrinsics Guide
#include <emmintrin.h>
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
int blocks;
/*loop Unrolling */
blocks = n >> 2U;
while (blocks > 0U) {
_mm_storeu_ps(z, _mm_add_ps(_mm_loadu_ps(x), _mm_loadu_ps(y)));
x += 4;
y += 4;
z += 4;
/* Decrement the loop counter */
blocks--;
}
/* If the blockSize is not a multiple of 4, compute any remaining output samples here.
** No loop unrolling is used. */
blocks = n % 0x4U;
while (blocks > 0U) {
(*z++) = (*x++) + (*y++);
/* Decrement the loop counter */
blocks--;
}
}
可以看到我们仅仅是对loop中代码更换成了 SSE 代码,一次性加载 4个浮点_mm_loadu_ps,并对4个浮点做一个性的向量相加_mm_add_ps, 最后在将运算后的数值返还给输出指针 _mm_storeu_ps。
NEON intrinsics
有了 SSE 优化,之后优化 ARM 芯片上的 NEON 指令就轻松许多了。
-
NEON API 的参考文档:NEON Intrinsics Reference
#include <arm_neon.h>
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
int blocks;
/*loop Unrolling */
blocks = n >> 2U;
while (blocks > 0U) {
vst1q_f32(z, vaddq_f32(vld1q_f32(x), vld1q_f32(y)));
x += 4;
y += 4;
z += 4;
/* Decrement the loop counter */
blocks--;
}
/* If the blockSize is not a multiple of 4, compute any remaining output samples here.
** No loop unrolling is used. */
blocks = n % 0x4U;
while (blocks > 0U) {
(*z++) = (*x++) + (*y++);
/* Decrement the loop counter */
blocks--;
}
}
其他
下面的 MKL 和 CMSIS 的调用就几乎是傻瓜式调用了,主要是参考文档的阅读会花费些时间。
-
MKL 的 API 优化参考:Developer Reference for Intel® Math Kernel Library 2020 - C
#include <mkl.h>
void tpd_vsadd(const float* x, const float* y, float* z, int n) {
vsAdd(n, x, y, z);
}
- CMSIS DSP 优化:CMSIS DSP Software Library
当然相比于看接口文档,我还是比较推荐看Arm Software 官方开源代码 CMSIS github,和嵌入式打过交道的小伙伴一定懂。
#include <arm_math.h>
void tpd_vsadd(const float32_t* x, const float32_t* y, float32_t* z, int n) {
arm_add_f32(x, y, z, (int)n);
}
总结
文中仅仅介绍了浮点的向量加优化,当你扩展到点乘、点积等也就会得心应手了。
另外,我们知道神经网络中会有大量的浮点运算,在有些浮点运算能力偏弱的平台上,如何用整型定点计算替换浮点运算,是工程化的重要一步(关于定点优化可以参考我的另一篇文章量化压缩在神经网络中的应用)。
加入 SIMD 或 DSP 的指令优化一定程度上会使得代码更加高效,比如当浮点转换成 int8 定点时, SSE/NEON 可以一次性加载16个 int8 整型数。
对于 SIMD 的优化,我们最需要的是对官方文档和优秀开源代码的有一定阅读能力,同时加上一点耐心就好。